
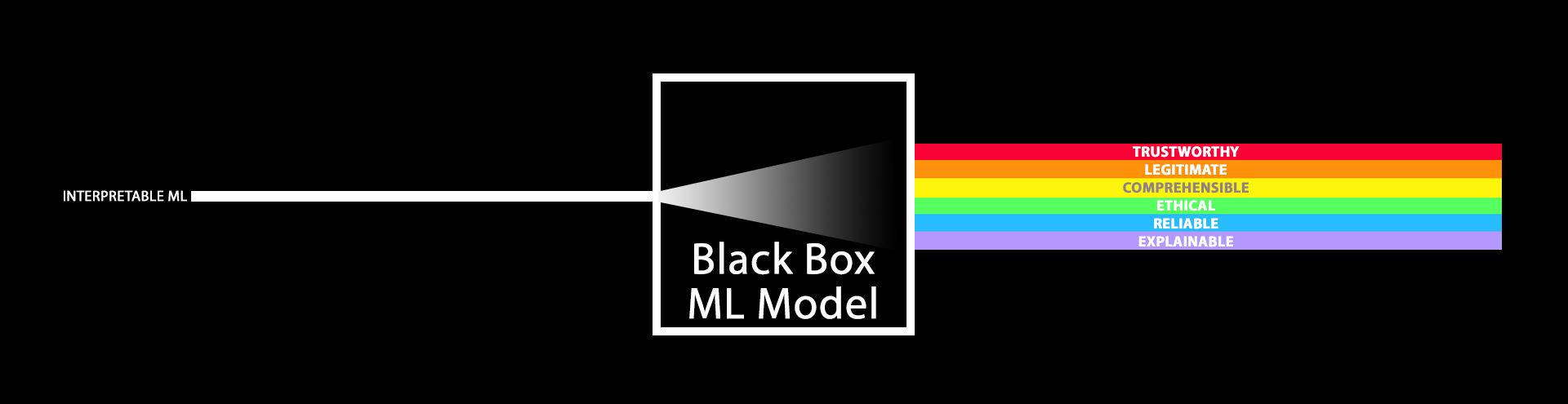
Introduction
Machine learning (ML) is currently being used in a variety of sectors including manufacturing, with applications of predictive maintenance, banking, with credit scoring and risk management, as well as insurance, for fraud detection and damage estimation. Finally, healthcare, with the effectiveness of care delivery and the diagnosis or prognosis of a wide range of diseases, is another area where ML is offering solutions. However, many ML models might be characterized as being inaccessible to humans because of their internal encoding or amount of complexity. Such models are called black-box models. Methods for analyzing and interpreting ML models to make the internal logic and output of algorithms accessible and easily understandable are required in applications employing ML where decisions might impact human lives or incur economic loss, ensuring that these applications are inclusive and safe.

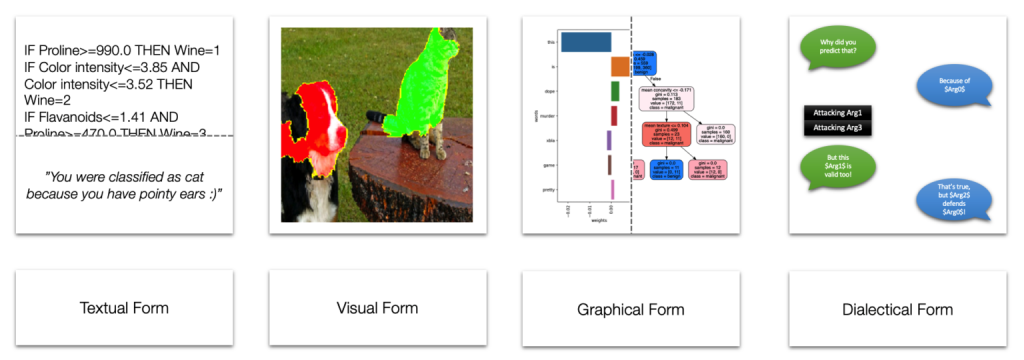
The topic of interpretable machine learning investigates the techniques that enable machine learning models to be interpretable. While certain models can be interpreted on their own as they are intrinsically interpretable, black-box models require additional techniques to be interpreted. The various interpretability techniques proposed fall into two broad categories: model-agnostic and model-specific. The interpretations produced either by the interpretability techniques or directly from the ML model can be global or local. Global interpretations cover the overall structure and mechanism of the ML model, while local interpretations focus on explaining a single prediction made by the ML model. Additional criteria driving the categorization of interpretability techniques include their adaptability to diverse data types, runtime performance, training data requirements, and user cognitive level, among others. Rules, trees, visuals with highlighted parts, feature importance, or even entire phrases can be used as interpretations.
Our contributions
Our lab has made significant contributions to the field of interpretable machine learning through a large number of publications and theses. Several of them [P2, P4, and P8] investigate the interpretability of Random Forests models in binary, multi-class, multi-label, and regression tasks, providing rules as explanations. Several studies have focused on the interpretability of neural networks, with some focusing on classic neural architectures [P3, P9, M4, M5], while others consider transformer architectures [P1, B1, B2]. The topic of the explainability of dimensionality reduction has also been investigated [P5, B4]. Another of our works focuses on evaluating interpretability and proposes a meta-explanation schema for even better interpretations [P7]. In this work, argumentation is also used to help the user trust both the model and the interpretability technique. In two theses, we also explored the development of assistant bots with user interfaces that leverage the interpretability techniques we have proposed to build a tool that can present the interpretations to the end user in a friendlier manner. Finally, we have also explored interpretability through the scope of several domains, including hate speech detection [P1, P3, B1, B2], biomedicine [P1, M1], and predictive maintenance [P6, M2, M3].
Related Projects
Publications
- An Attention Matrix for Every Decision: Faithfulness-based Arbitration Among Multiple Attention-Based Interpretations of Transformers in Text Classification, Nikolaos Mylonas, Ioannis Mollas, Grigorios Tsoumakas, Arxiv, 2022
- Local Multi-Label Explanations for Random Forest, Nikolaos Mylonas, Ioannis Mollas, Nick Bassiliades, Grigorios Tsoumakas, XKDD-ECMLPKDD22 in Grenoble, France, September 19-23, 2022
- LioNets: a neural-specific local interpretation technique exploiting penultimate layer information, Ioannis Mollas, Nick Bassiliades, Grigorios Tsoumakas, Applied Intelligence, Springer, 2022
- Conclusive local interpretation rules for random forests, Ioannis Mollas, Nick Bassiliades, Grigorios Tsoumakas, Data Mining and Knowledge Discovery, Springer, 2022
- Local Explanation of Dimensionality Reduction, Avraam Bardos, Ioannis Mollas, Nick Bassiliades, Grigorios Tsoumakas, SETN2022, Corfu, Greece (currently on arXiv preprint arXiv:2204.14012), 2022
- VisioRed: A Visualisation Tool for Interpretable Predictive Maintenance, Spyridon Paraschos, Ioannis Mollas, Nick Bassiliades, IJCAI-21 in Canada, Montreal-themed Virtual Reality, 19th-26th August, 2021
- Altruist: argumentative explanations through local interpretations of predictive models, Mollas, Ioannis, Nick Bassiliades, Grigorios Tsoumakas, SETN2022, Corfu, Greece (currently on arXiv preprint arXiv:2010.07650), 2020
- LionForests: Local Interpretation of Random Forests, Ioannis Mollas, Nick Bassiliades, Ioannis Vlahavas, Grigorios Tsoumakas, New Foundations for Human-Centered AI (NeHuAI 2020) of 24th European Conference on Artificial Intelligence (ECAI 2020), Santiago de Compostella, Spain, 4 September 2020.
- LioNets: Local Interpretation of Neural Networks through Penultimate Layer Decoding, Ioannis Mollas, Nick Bassiliades, Grigorios Tsoumakas, AIMLAI-XKDD-ECMLPKDD19 in Würzburg, Germany, September 16-20 2019
MSc Theses
- Interpretable Multi-Label Learning in Biomedical Texts, Konstantinos Giantsios, July 2022
- Interpretable Predictive Maintenance: Global and Local Dimensionality Reduction Approach, Georgios Christodoulou, May 2022
- Elevating Interpretable Predictive Maintenance through a Visualisation Tool, Spyridon Paraschos, April 2021
- LionLearn: Local interpretation of black box machine learning models, Ioannis Mollas, March 2020
BSc Theses
- Multi-label assisted interpretable hate speech detection, Lukas Stogiolaris, July 2022
- Evaluation of Interpretability Techniques on Hate Speech Detection, Achilleas Toumpas, March 2022
- Interactive Representation of Machine Learning Model Explanations through Altruist Bot, Athanasios Mpatsioulas, October 2021
- Interpretable Dimensionality Reduction, Avraam Bardos, October 2021
- AutoLioNets: Automatic decoder construction and training for the LioNets interpretation technique, Alexandros Tassios, March 2021
- LionForests Bot: Interactive dialogue between user-machine learning model via explanations, Ioannis Chatziarapis, November 2020
- Explaining Sentiment Prediction by Generating Exemplars in the Latent Space, Orestis Panagiotis Lampridis, September 2019